Weifeng Lin (林炜丰)
I am currently a second-year Ph.D. student at the MMLab, The Chinese University of Hong Kong (CUHK), supervised by Hongsheng Li. I earned both my Bachelor's and Master's degrees from the South China University of Technology in 2021 and 2024, respectively, being advised by Lianwen Jin.
Research Interest: Interative Vision-Language Models, the Large-scale Video Generation Model, and the Intersection of Robotics. I am also deeply committed to contributing to open-source projects, believing they are a cornerstone for the sustainable growth of the AI community.
Email: wflin37@gmail.com

News
- [09/2025] Three papers have accepted by NeurIPS 2025
- [08/2025] Received Hong Kong Postgraduate Scholoarship, 2025
- [01/2025] Two papers have accepted by ICLR 2025
- [05/2024] Invited talk on IDEA-CVR about "Draw-and-Understand", a project on visual prompting for VLMs.
- [12/2023] Alibaba Cloud Outstanding Research Intern (Top 5% Award)
- [06/2023] Invited talk on TechBeat for "Scale-Aware Modulation Meet Transformer".
Selected Publications


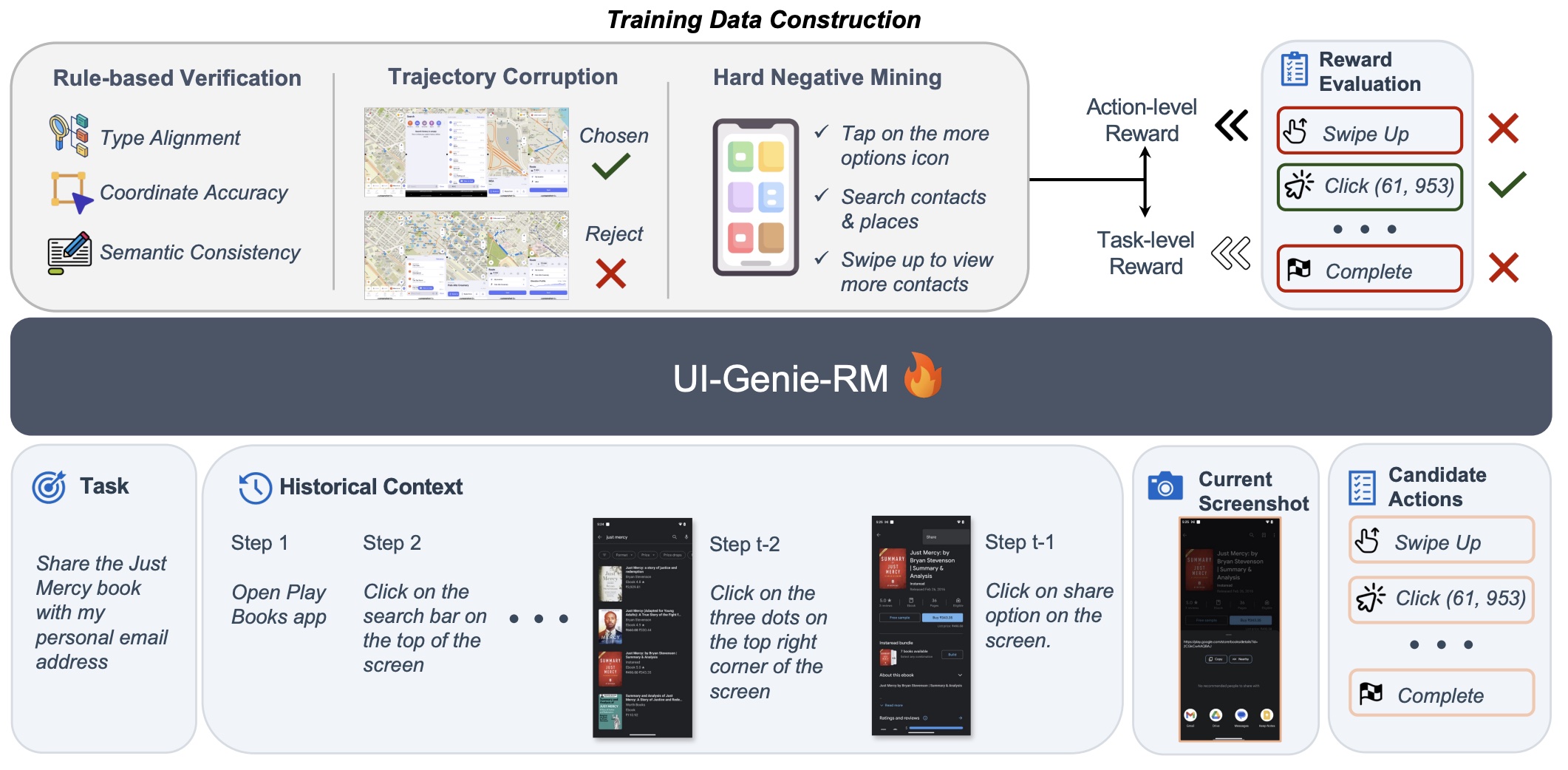
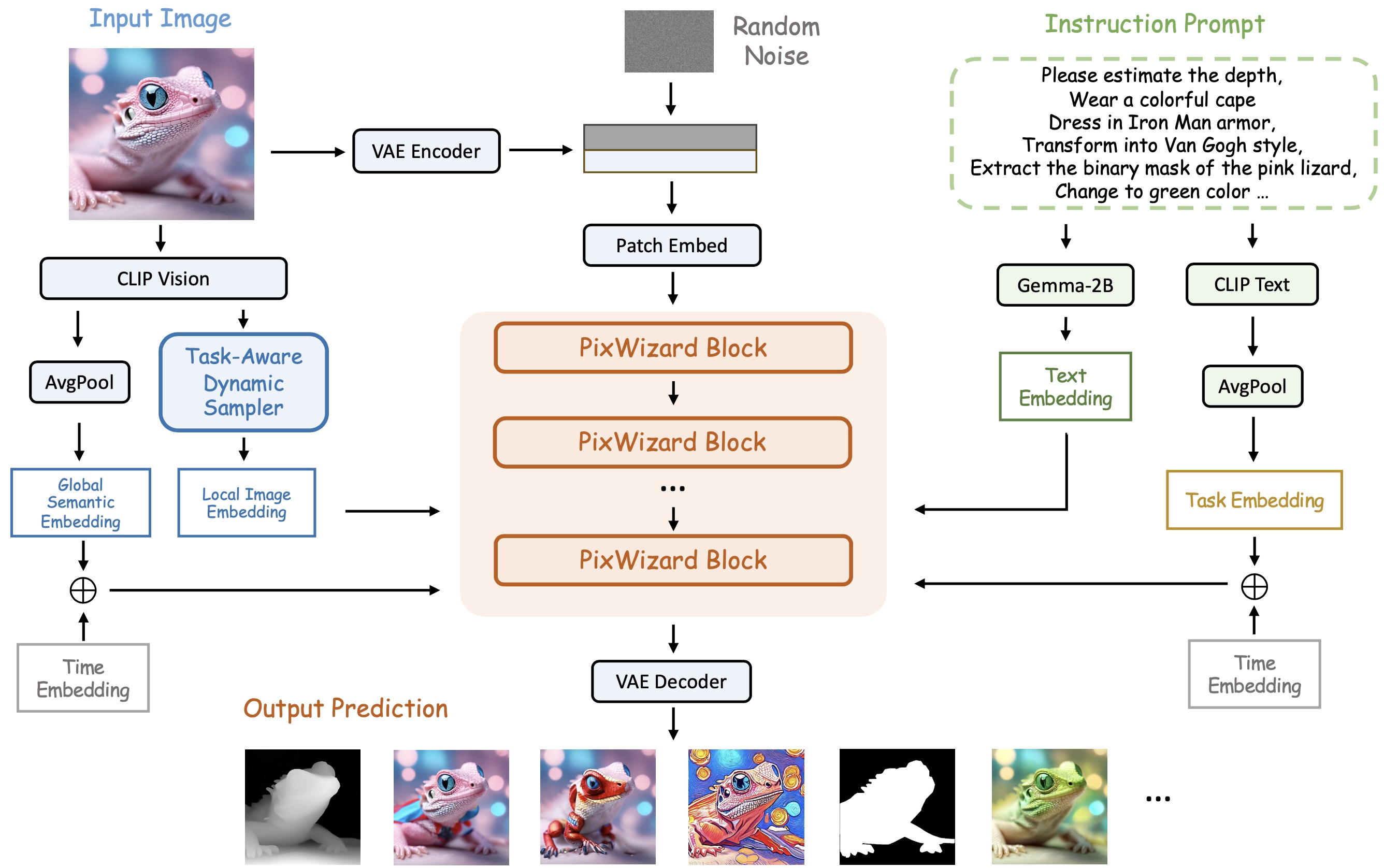


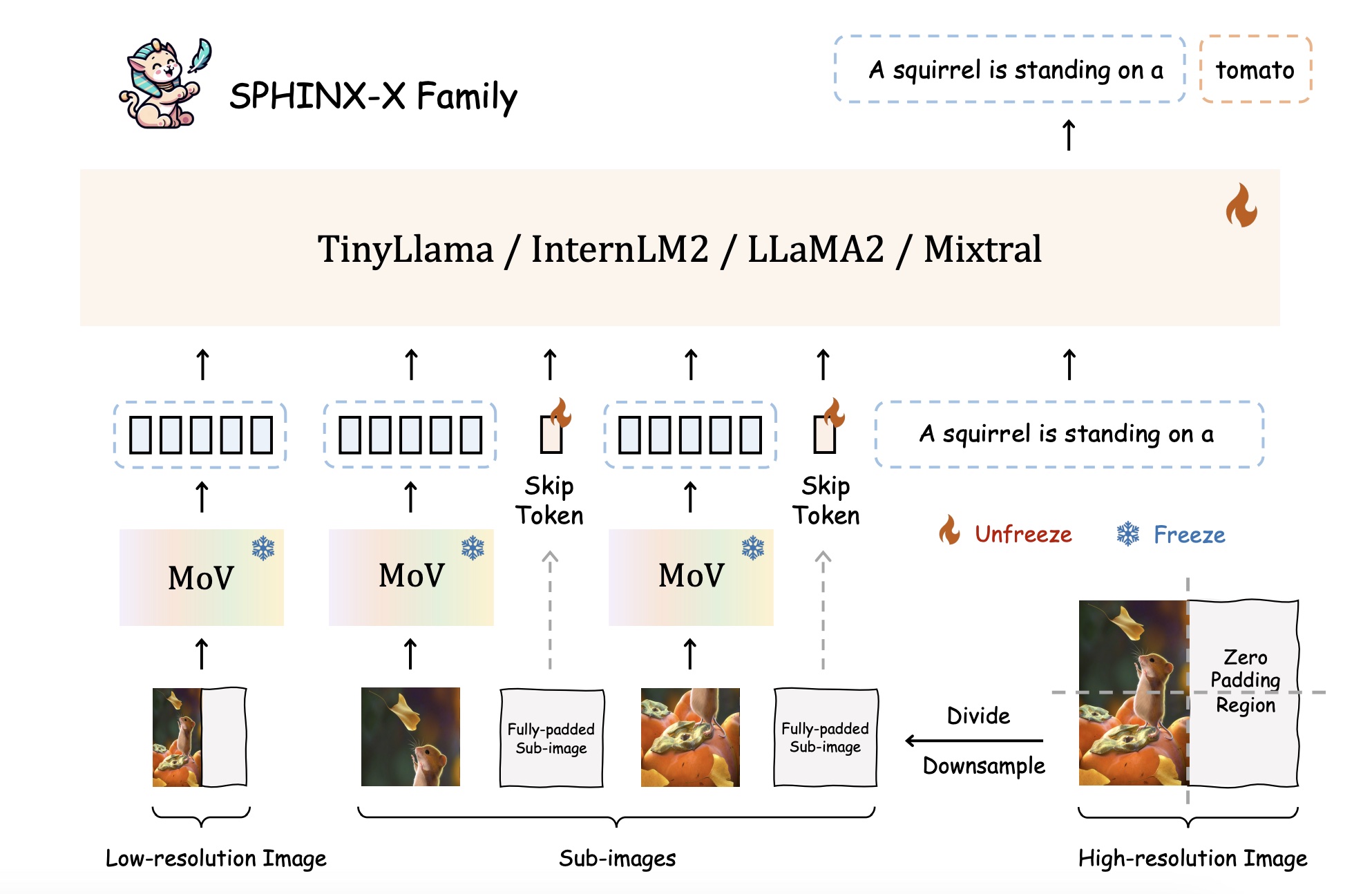
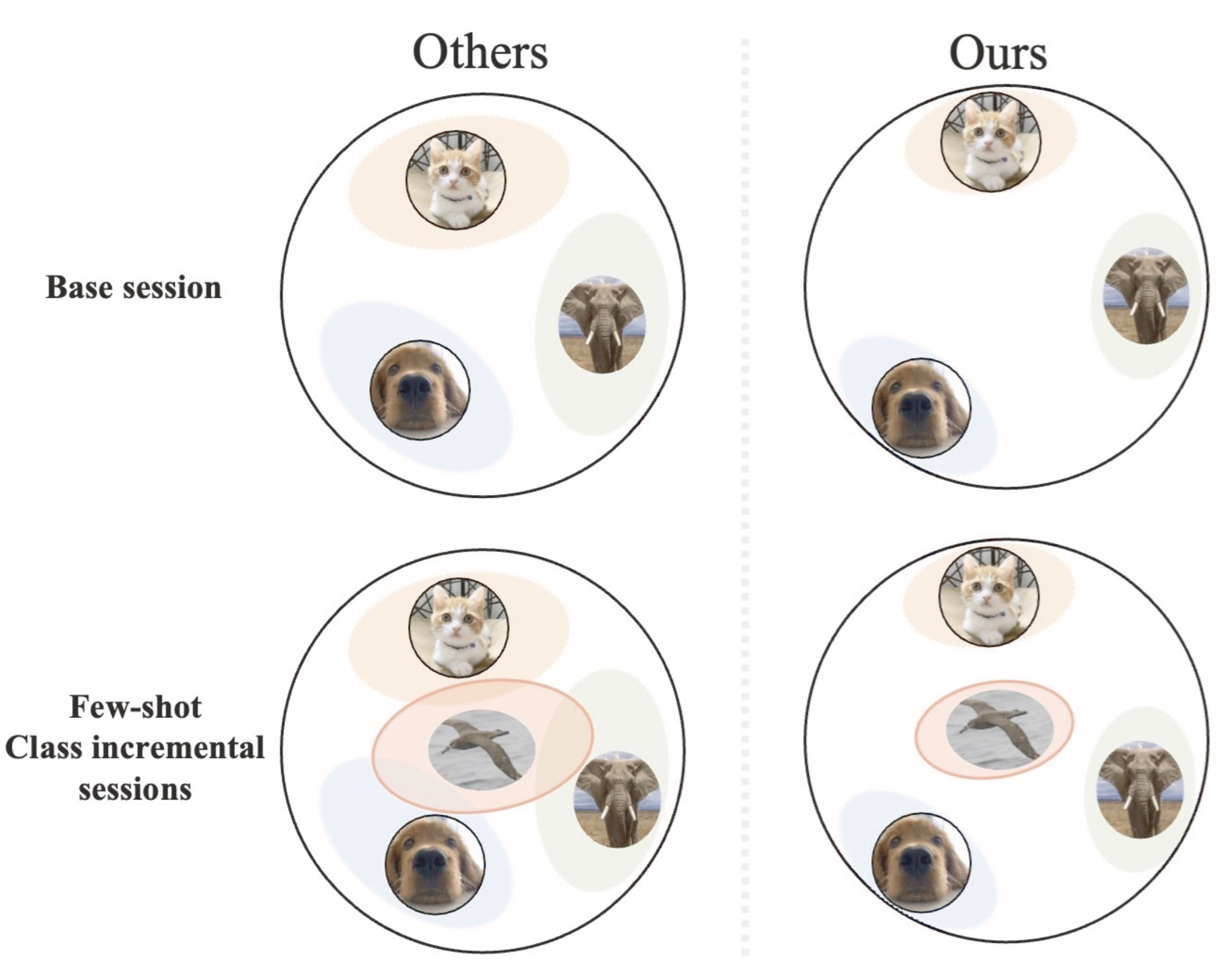
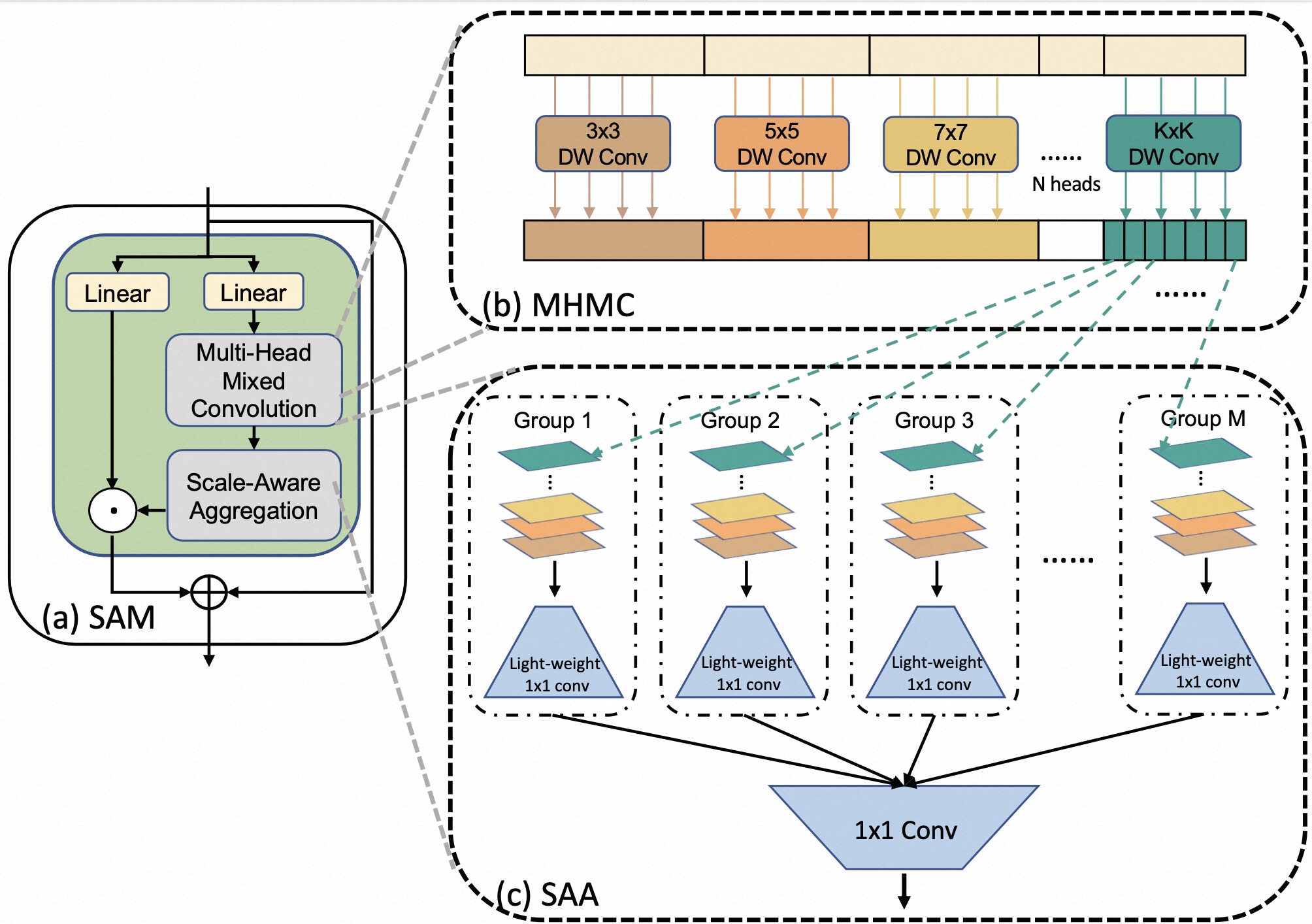
Experience
Research Intern, Robotics
2025.09 - 2026.01
Shenzhen, China
Research Intern, Agent
2024.11 - 2025.06
Shenzhen, China
Research Intern, OpenGVLab
2024.01 - 2024.06
Shanghai, China
Research Intern, Machine Learning Platform for AI
2022.11 - 2023.12
Hangzhou, China
Reviewer Service
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
International Conference on Computer Vision (ICCV), 2025
International Conference on Machine Learning (ICML), 2025
International Conference on Learning Representations (ICLR), 2024, 2025
Conference on Neural Information Processing Systems (NeurIPS), 2024, 2025
AAAI Conference on Artificial Intelligence (AAAI), 2025
|
|